Language Models are Few Shot Learners - Meta Learning with GPT-3
Analyzing the paper "Language Models are Few-Shot Learners", exploring GPT-3's meta-learning abilities in Zero, One, and Few-Shot scenarios.
ChatGPT, GPT-4, Bing Chat, Claude 2, Llama 2, Bard, ... the list most likely could go on indefinitely or at least for a very long time. The hype about large language models is real, and will probably hold on for quite a while.
So today, let's dive a bit deeper into the capabilities of such large language models by analyzing and discussing the paper "Language Models are Few-Shot Learners" by Tom B. Brown et al. from the OpenAI team which explores, as the name implies, GPT-3s Meta-Learning capabilities in the Zero, One and Few-Shot setting.
What is language modeling?
Language modeling is a task in natural language processing, for which the goal is to predict the next word or sequence of words based on previous words.
By analyzing patterns, context, and syntax in large amounts of text, language models can generate coherent and relevant passages of text.
These models have a wide array of applications, from autocorrect and predictive typing on smartphones to machine translation and AI chatbots.
High-Level Main Concepts
Now that the basic fundamentals are clear, we can dive into the main concepts which the paper explores.
Meta-Learning
Meta-learning involves training a model to acquire fundamental skills, such as pattern recognition, during its training phase which allows it to rapidly adapt to new tasks during the inference phase.
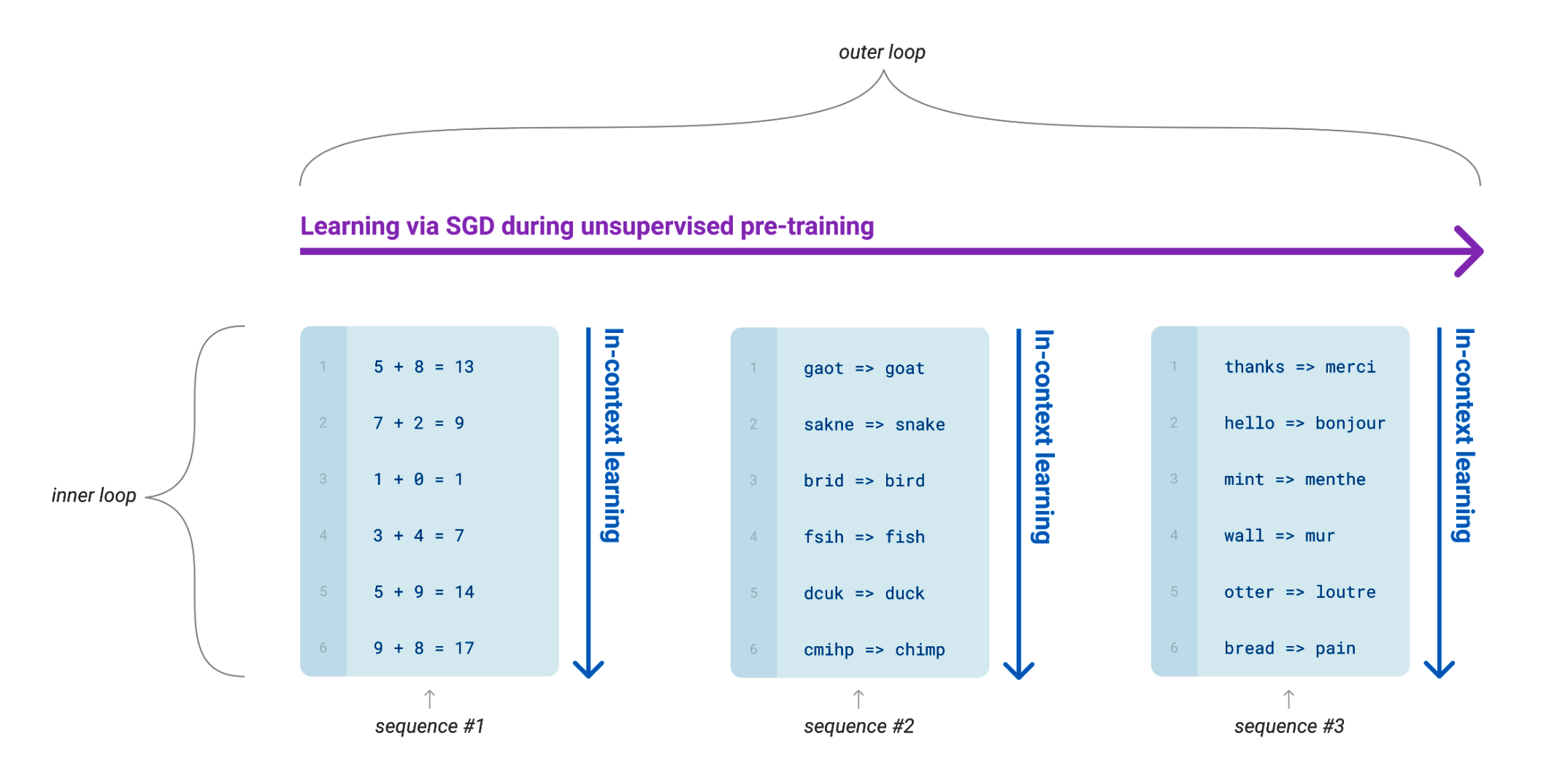
In the paper, the concept of unsupervised pre-training is seen as an 'outer loop' of learning, where the language model acquires a wide range of skills. During this 'outer loop', the model generates sequences of text that encompass various 'inner loop' tasks, such as performing arithmetic operations, correcting typos, and translating text.
This 'inner loop' is representative of a type of learning known as 'in-context learning'. In this process, the model learns to adapt to a specific task within the provided context. The model's capacity to swiftly adjust based on context is subsequently utilized to tackle new tasks during the inference or application phase.
Few-Shot Learning
Few-shot learning is a methodology used in machine learning where a model is designed to gain useful knowledge from a small set of examples - typically ranging from 1 to 100 - and to use this knowledge to adapt quickly to new tasks with a similar limited amount of data.
The key idea is that with a well-designed learning process, a model can perform effectively on a new task after seeing only a handful of examples, thus reducing the need for large amounts of task-specific training data.
In the context of our paper, few-shot learning refers to providing the model with a limited number of context examples during the inference phase, allowing the model to generalize and handle new inputs based on these examples.
Typical Approach: Fine-Tuning
In the fine-tuning approach, a model that has already been pre-trained on a large dataset is further refined by training it on a dataset specific to the task at hand. The weights of the model are updated during this process to better suit the new task.

However, a significant drawback of this approach is that it requires a large amount of task-specific data to be effective, which may not always be readily available or feasible to obtain. This approach is not used for GPT-3 in our paper.
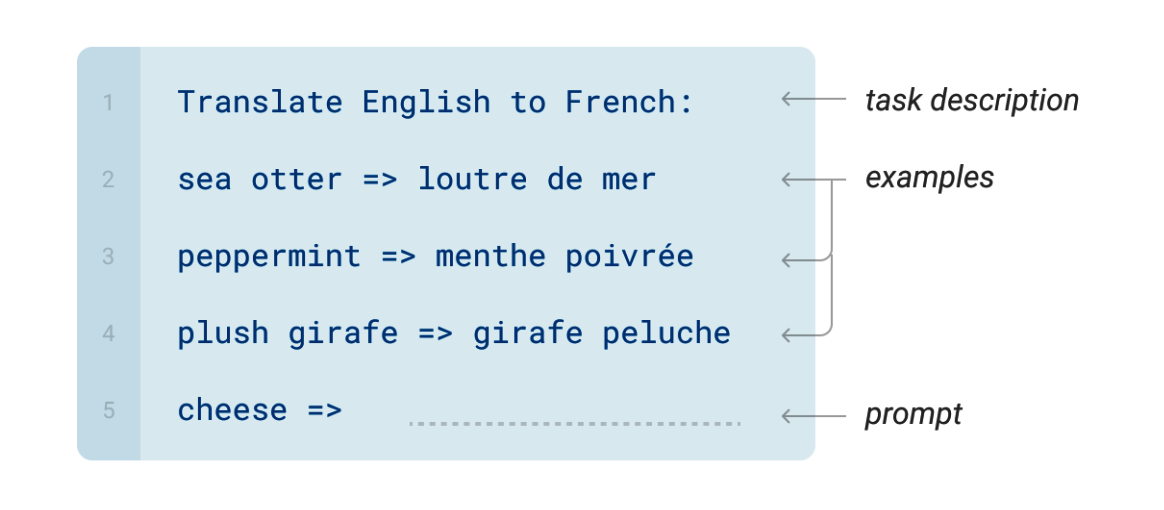
In-Context Few-Shot Learning
This approach is a departure from the fine-tuning methodology. In few-shot learning, during the inference phase, the pre-trained model is provided with a description of the task, a few (typically 1 to 100) labeled examples, and an example where a prediction is required. The model then uses this context to make a prediction for the task.
Importantly, no gradient updates are made during this process; instead, the model leverages its existing knowledge to adapt to the new task.
This significantly reduces the need for large amounts of task-specific data. This approach is used for GPT-3 in our paper.
Combine Meta-Learning and Few-Shot Learning
The paper integrates the concepts of meta-learning and few-shot learning in the context of large language models.
During unsupervised pre-training, the language model learns about various tasks. At inference time, the model is then presented with zero, one, or a "few" examples of a new task, allowing it to calculate the correct output without any fine-tuning.
Research has shown that a models meta-learning capability improves smoothly with increasing its model size. In the light of these findings, the paper pursues two main objectives:
- Firstly, it tests the scaling hypothesis of meta-learning by training and testing several GPT-3 variants of different sizes.
- Secondly, it explores the capacities of zero, one, and "few"-shot learning across a variety of NLP benchmark tasks. This is achieved without any fine-tuning, with the task description and examples given via a prompt.
Model Architecture and Training
GPT-3, like its predecessor GPT-2, uses the same Transformer model and architecture. However, it has been trained in eight different sizes, from 125 million parameters up to a full-scale model with 175 billion parameters. This range allows researchers to study how scaling impacts learning capability and performance.
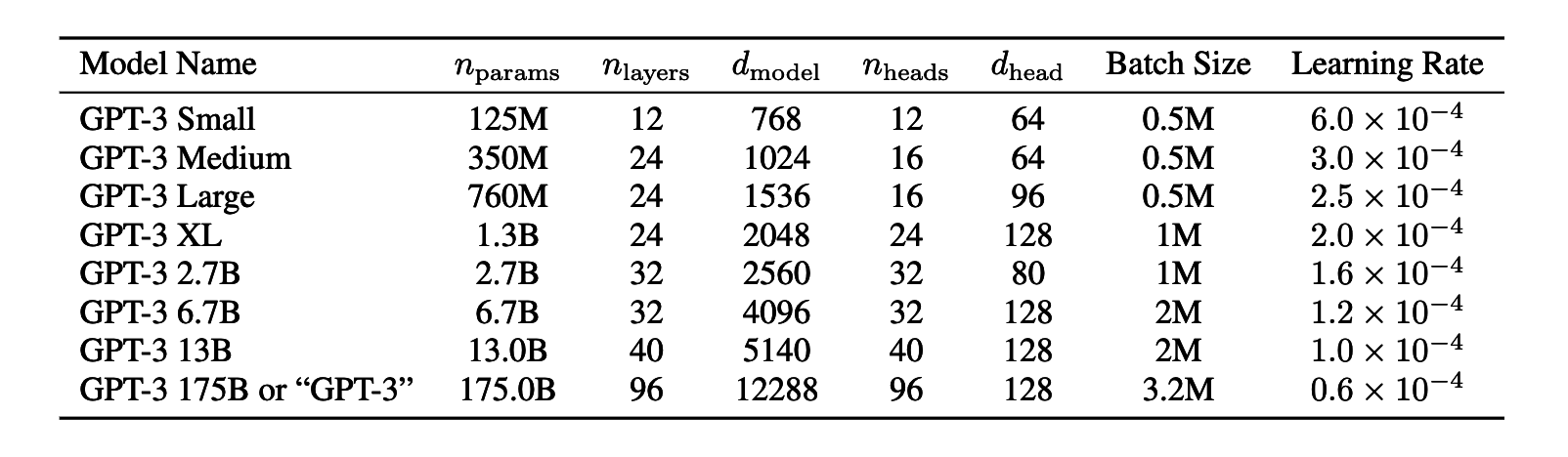
Previous research has shown that larger models can handle larger batch sizes but require a smaller learning rate for stable training.
To balance efficiency and learning robustness, the researchers used the gradient noise scale, a metric representing the signal-to-noise ratio of the gradient across training examples, to determine optimal batch sizes.
The resulting batch sizes enabled effective and efficient training of the various GPT-3 model sizes.
Datasets
The paper outlines the use of various datasets in the training of all GPT-3 variants. Each variant is trained on a tailored version of CommonCrawl, a web-scraped dataset. This custom version was created by filtering CommonCrawl based on its similarity to a selection of high-quality reference corpora.
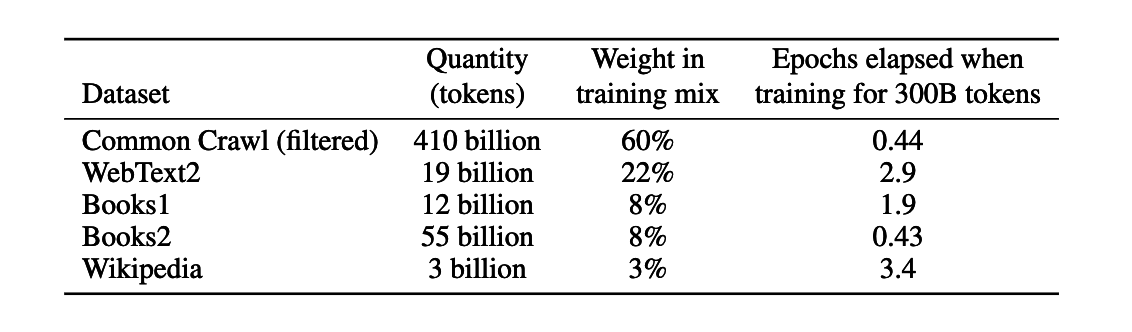
In order to minimize redundancy and maintain the integrity of the validation dataset, fuzzy deduplication was applied at the document level. Furthermore, high-quality reference corpora were incorporated into the training mix to supplement CommonCrawl and enhance its diversity.
These reference corpora include an expanded version of the WebText dataset, two book datasets known as Books1 and Books2, and the English-language Wikipedia. The combination of these diverse and extensive datasets supports the robust training and evaluation of the various GPT-3 models.
Results
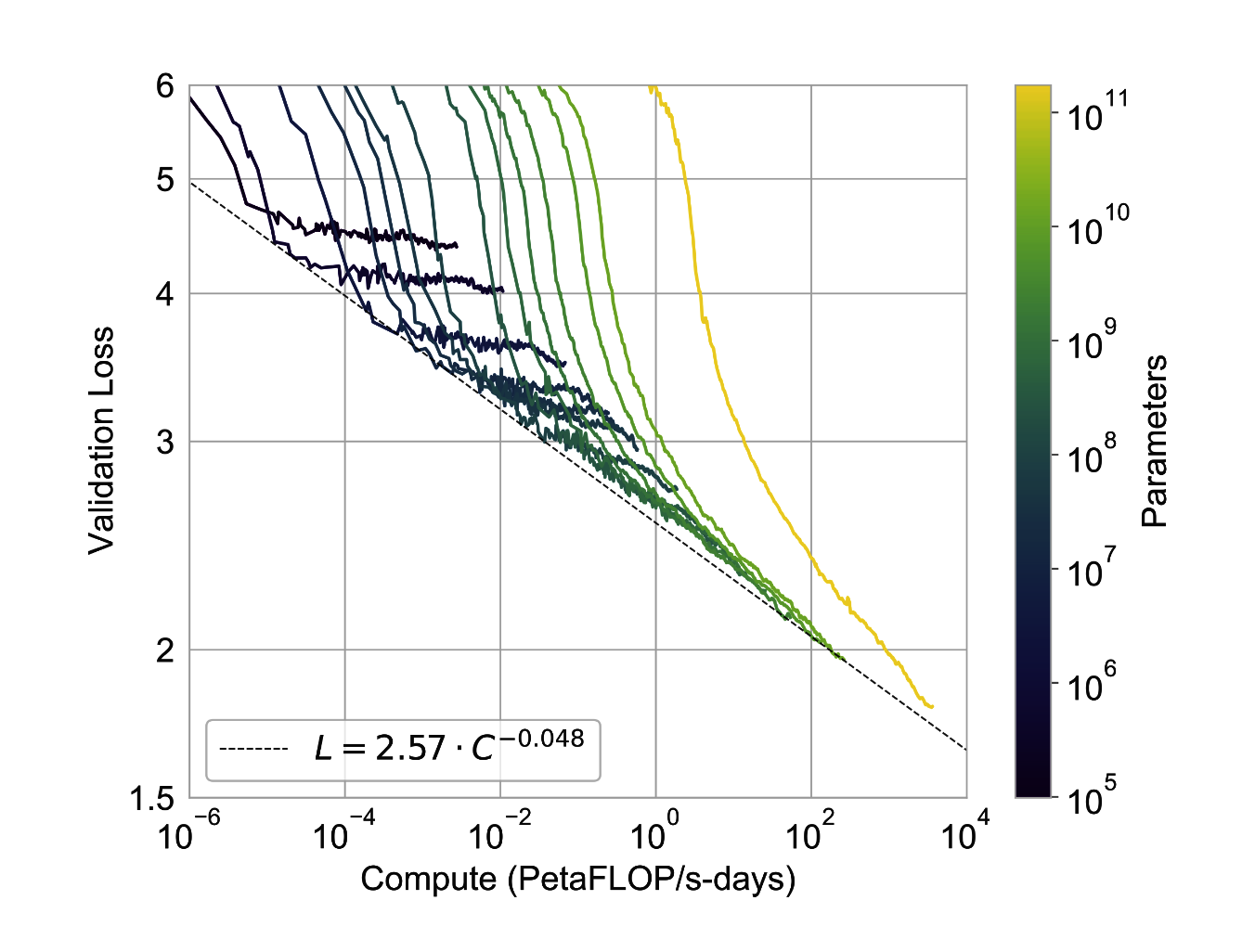
The results of the paper showcase a smooth scaling of model performance with increased computational resources. The performance of the models appears to follow a power-law trend with the amount of compute used in the training process, indicating that larger models which utilize more compute during training tend to perform better.
Language Modeling
The paper presents GPT-3's performance on several natural language processing tasks associated with language modeling:
In the Penn Tree Bank (PTB) task, which involves part-of-speech tagging, GPT-3 was tested in a zero-shot setting. Despite some parts being left out due to training dataset overlap, GPT-3 achieved a new state-of-the-art score, surpassing the previous benchmark by a significant 15-point margin.

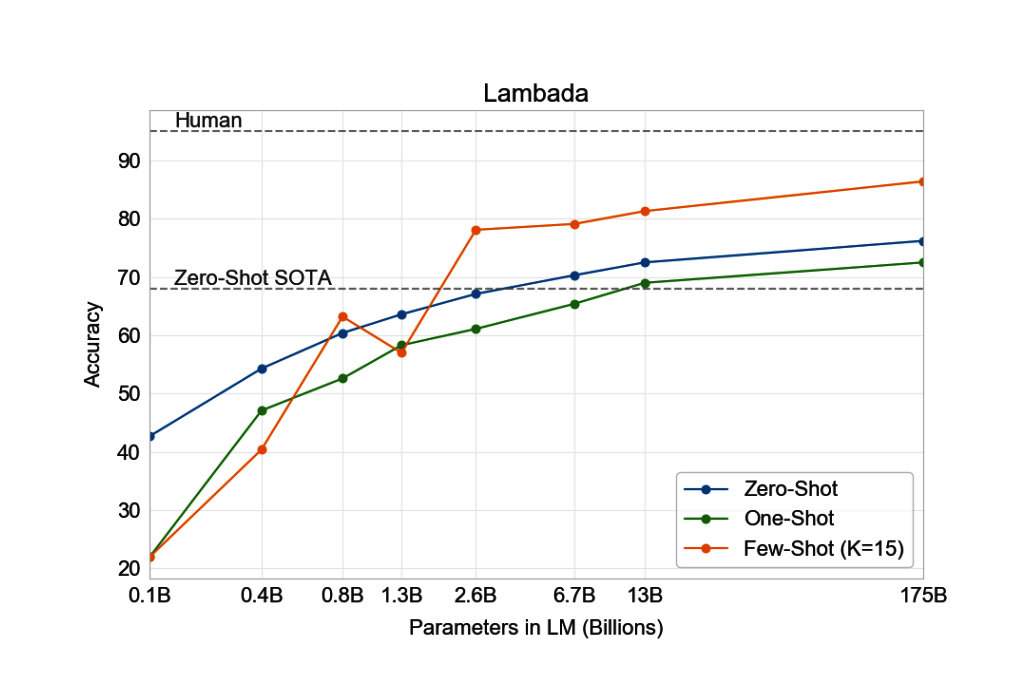
In the LAMBADA task, which involves predicting the next word using the context provided, GPT-3 managed to improve over the current state-of-the-art results in the zero, one, and few-shot setting.
In the HellaSwag task, a more challenging task that involves next sentence classification, GPT-3 was able to outperform a fine-tuned 1.5B parameter language model.
However, in the StoryCloze 2016 task, GPT-3's performance was about 4% lower than a fine-tuned state-of-the-art model based on BERT. Despite this, it's noteworthy that GPT-3 did improve over the previous zero-shot results by a significant 10%.
(Closed-Book) Question Answering
In the realm of closed-book question answering, which tests a model's capacity to answer factual questions without access to external knowledge bases, GPT-3 showcased variable performance across different tasks:
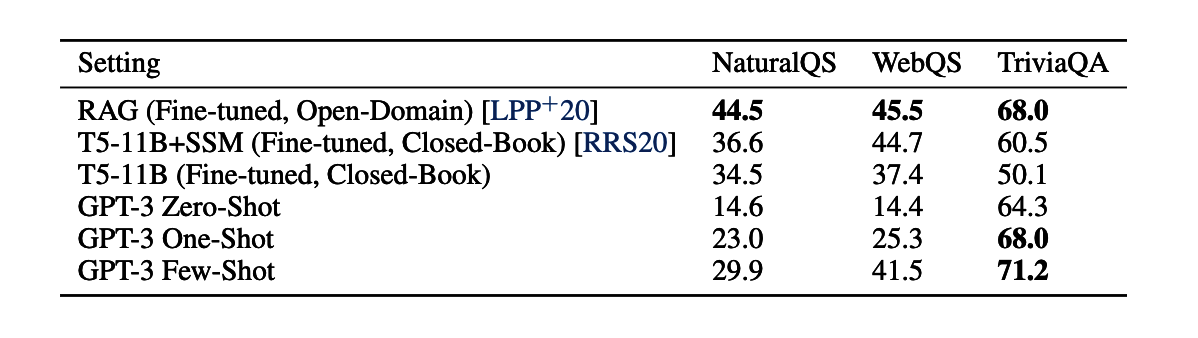
- Natural Questions and WebQuestions: These tasks require the model to read and comprehend lengthy articles or leverage a large knowledge graph respectively to generate answers. GPT-3 struggled somewhat with these tasks, generally failing to reach state-of-the-art results.
- TriviaQA: This task entails answering complex questions based on Wikipedia articles and other web content with extended context. Here, GPT-3 demonstrated impressive capabilities, matching or even surpassing the performance of all fine-tuned comparison models, achieving results on par with the current state-of-the-art.
Furthermore, in a variety of other question answering tasks, GPT-3 presented strong performance. It outperformed a fine-tuned T5-11B model on TriviaQA, equaled the state-of-the-art in open-domain question answering even in the one-shot setting, and approximated the performance of a fine-tuned RoBERTa baseline on the ARC dataset.
On the CoQA (Conversational Question Answering Challenge) task, GPT-3 came within 3 points of the human baseline in the few-shot setting. In the DROP (Discrete Reasoning Over the content of Paragraphs) task, it outperformed a fine-tuned BERT baseline, although it didn't quite match human performance or other state-of-the-art methods.
These results reflect the varied capabilities of GPT-3 across diverse question answering tasks.
Translation
Translation tasks in language models can be tricky due to the intricate balance between understanding the source language and accurately rendering it into the target language.
With a training data comprised of mostly English content (93%) but also a portion of non-English content (7%), GPT-3 diverges from conventional unsupervised translation methods that frequently employ back-translation to bridge languages in a controlled manner.
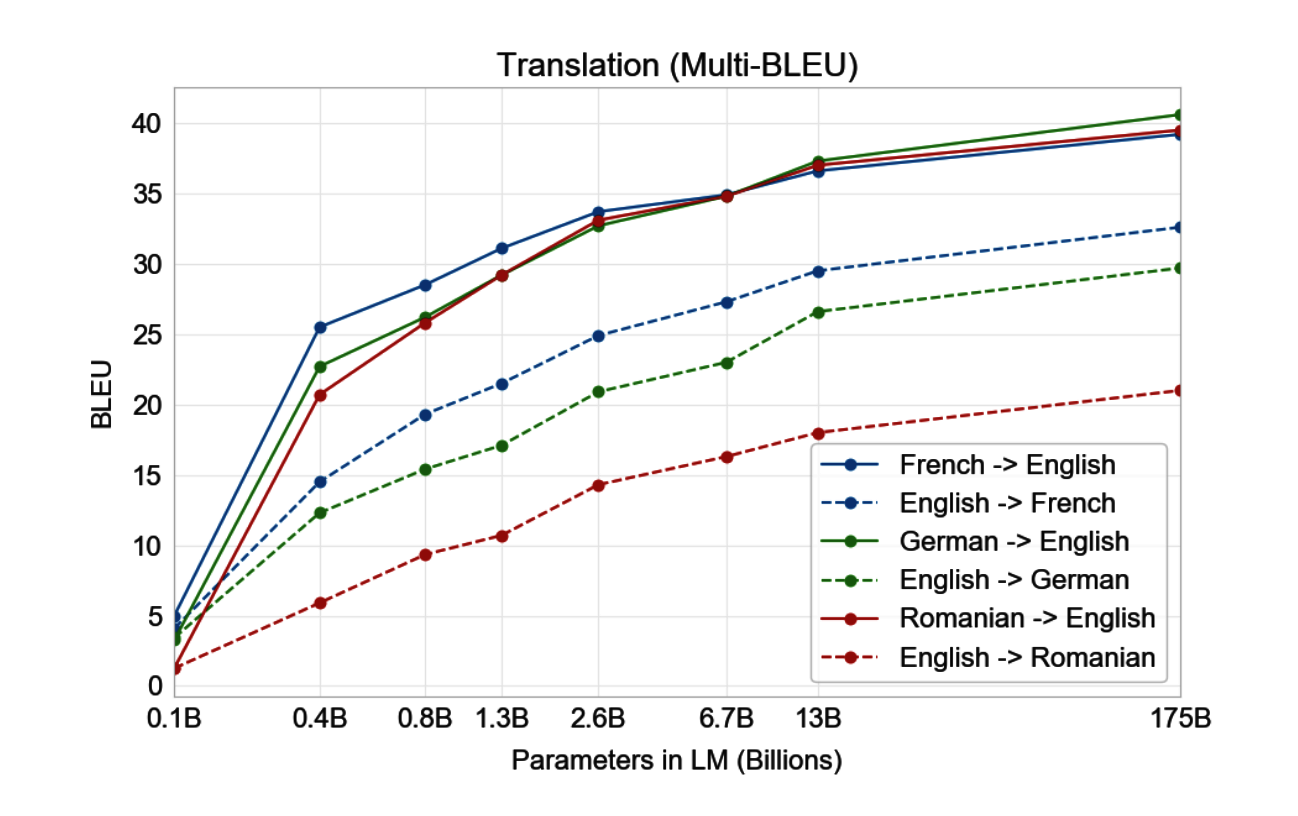
Interestingly, GPT-3 showed better performance in tasks translating from other languages into English than vice versa. This discrepancy could stem from the fact that the BPE tokenizer originally employed by GPT-2 and used by GPT-3 was designed primarily for English-only datasets.
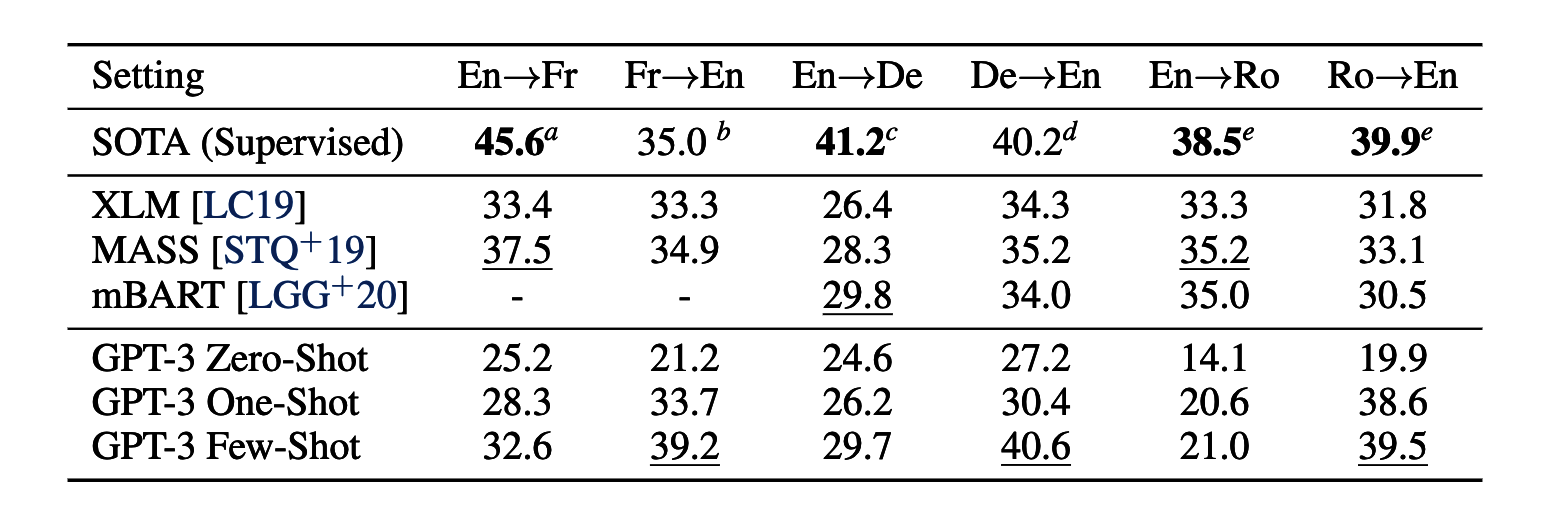
In terms of general performance, GPT-3 achieved average results when tasked with translating English into other languages. However, when translating from a different language to English, it performed quite well, even surpassing some unofficial state-of-the-art results.
These results indicate that while GPT-3 is adept at understanding and translating other languages into English, there remains room for improvement in its ability to translate English into other languages.
SuperGLUE
SuperGLUE is a standard benchmark used to evaluate Natural Language Understanding (NLU) tasks, consisting of several diverse datasets. GPT-3's performance has also been evaluated across these various datasets, and it exhibited a broad spectrum of results.
In some tasks, GPT-3 demonstrated near state-of-the-art performance, such as in COPA (Choice of Plausible Alternatives) and ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset). These tasks test the model's common sense reasoning and understanding of textual content, respectively.
However, GPT-3 did not fare as well on other tasks, including WiC (Words-in-Context), which tests the model's ability to interpret context-sensitive word meanings. The model performed equivalently to random chance on this task.
The authors suggest that GPT-3's weaker performances could be attributed to its difficulties in tasks involving comparisons between two sentences or snippets. This theory is also supported by the model's low scores on RTE (Recognizing Textual Entailment) and CB (Commitment Bank).
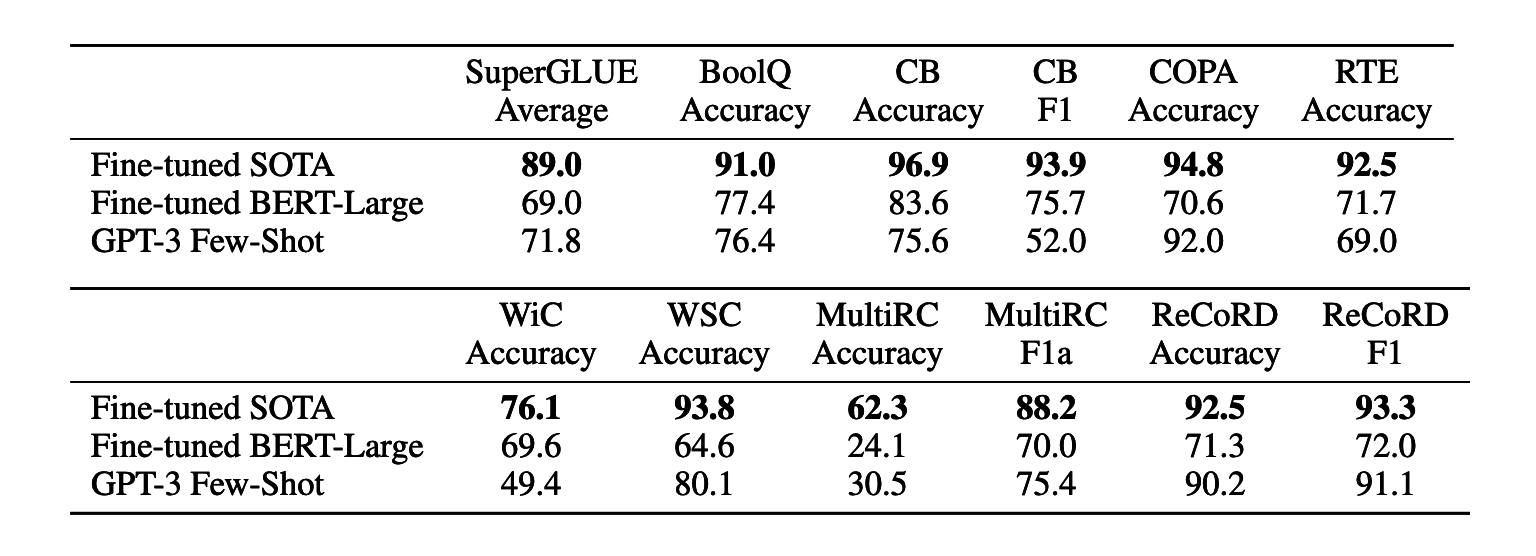
Despite these weaknesses, it's important to note that GPT-3 outperformed a fine-tuned BERT-large model on 4 out of the 8 tasks and approached state-of-the-art results on two tasks. This performance suggests that, while there are areas for improvement, GPT-3's performance on NLU tasks can be quite strong.
Conclusion
GPT-3, being larger than GPT-2, uses a vast amount of data, raising potential concerns about benchmark data contamination and memorization. However, relative to a held-out validation set, the model does not significantly overfit its training data. To ensure accurate benchmarking, a clean version of each benchmark was produced, filtering out examples that had a 13-gram overlap with the training data.
Evaluations were conducted on both the clean and potentially contaminated benchmark datasets, with the results differing minimally in most cases. This suggests that, even if contamination is present, it does not significantly impact the results.
Large language models like GPT-3 have many benefits but also raise concerns. Potential misuse is one such concern, and energy efficiency is another, due to the substantial energy consumption associated with training these models.
GPT-3 still has some limitations in terms of text synthesis, notably repetition and occasional loss of coherence. It also presents challenges in terms of deployment due to its size. Task-specific distillation may be necessary at this scale. Also, as a pre-trained language model, GPT-3 lacks real-world context, which may limit its scalability through purely self-supervised prediction.
Despite these limitations, GPT-3 demonstrated strong performance on numerous NLP tasks and benchmarks in zero-shot, one-shot, and few-shot settings.
The model often matched or even exceeded the performance of state-of-the-art fine-tuned systems. This supports the idea that scaling up large language models can result in predictable performance improvements.