Running PyTorch Models for Inference at Scale using FastAPI, RabbitMQ and Redis
Exploring the architectural setup of how to host GPU intensive PyTorch deep learning models utilizing FastAPI, RabbitMQ and Redis in a scalable way.
Serving machine learning models isn't easy, many decisions have to be made in order to deploy them to production in a reliable and scalable way.
For simple models, it's perfectly reasonable to make them available as an synchronous API endpoint to be used by other services in our application structure. However, when dealing with neural networks, especially big ones which can only be efficiently trained via GPU, it might not be as easy.
As soon as we reach the point at which our model needs a GPU to do reasonably performant inference, we should carefully consider all possible options of serving our model.
Ideally, we'd like to utilize a GPU instance as good as possible solely on inference tasks, leaving the API necessities of making it available to much smaller, concurrency focused CPU instances.
To achieve this separation of concerns, we'll need a message broker to store our inference request, as well as a data storage solution to store the results for a certain amount of time
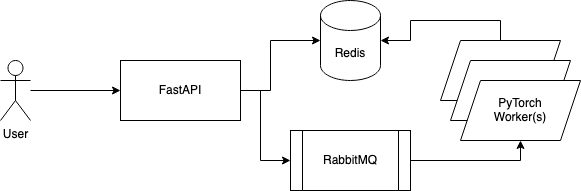
Which is why we are going to look at how we can build such a system. We'll serve up a PyTorch model, utilizing RabbitMQ as our message broker, FastAPI as our REST service and Redis as our in-memory storage backend to store the inference results.
A Simple MNIST Model
For the purpose of this post, we'll train an MNIST classification model, which allows us to classify a hand-drawn number.
It's one of the classic machine learning examples involving convolutional layers, which are commonly trained via GPU, so it makes for a good substitute of some other more advanced GPU heavy ML model we might be dealing with.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MNISTNet(nn.Module):
def __init__(self):
super(MNISTNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return outputmodel.py
To save some time, we use a trimmed down version of the PyTorch Example for MNIST, condensing it to the minimum of what's needed to get a fairly good solution.
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
from model import MNISTNet
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
torch.manual_seed(42)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_loader = DataLoader(datasets.MNIST('../data', train=True, download=True, transform=transform), batch_size=64)
test_loader = DataLoader(datasets.MNIST('../data', train=False, transform=transform), batch_size=64)
model = MNISTNet().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
for epoch in range(1, 3 + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
torch.save(model.state_dict(), "./mnist_cnn.pt")
if __name__ == '__main__':
main()
train.py
Starting the training process via python -m train, we can see good progress.
> Train Epoch: 1 [0/60000 (0%)] Loss: 2.321489
> Train Epoch: 1 [12800/60000 (21%)] Loss: 0.204598
> .
> .
> .
> Train Epoch: 3 [38400/60000 (64%)] Loss: 0.035516
> Train Epoch: 3 [51200/60000 (85%)] Loss: 0.122487
> Test set: Average loss: 0.0320, Accuracy: 9887/10000 (99%)Training is done for 3 epochs only, achieving 99% accuracy on the test set, barely enough for our goal. 😉
Afterwards, the model state dictionary is saved to mnist_cnn.pt
Setting up RabbitMQ and Redis
As our model is now ready to rock, we continue with the center parts of our desired setup, the RabbitMQ and Redis services. To make our lives a bit easier while in development, we spin up both of them using Docker.
docker run --rm -p 5672:5672 -p 15672:15672 -e RABBITMQ_DEFAULT_USER=my_user -e RABBITMQ_DEFAULT_PASS=my_password rabbitmq:3.10-managementdocker run --rm -p 6379:6379 redis:latestDone deal, easy as that, we have Redis running on port 6379, and RabbitMQ running on port 5672.
On port 15672 RabbitMQ additionally exposes its management interface, which can be used for debugging and checking the message brokers health, but we'll hopefully not need it for now.
Configuring FastAPI
The next part of our journey is to configure FastAPI. While doing that, we are extracting common RabbitMQ and Redis connectivity logic into a file called bridge.py. We are going to use it on both sides, the API and the PyTorch worker.
import pika
from pika import PlainCredentials
import redis
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host="localhost",
port=5672,
credentials=PlainCredentials("my_user", "my_password")
)
)
rabbitmq_client = connection.channel()
rabbitmq_client.queue_declare(queue="mnist_inference_queue")
redis_client = redis.Redis(host="localhost", port=6379)bridge.py
As it can be seen, the only thing this “bridge” is doing is connecting to the RabbitMQ message broker, as well as to the Redis data-store we spun up earlier. At a later stage, we might want to change the behavior to load the credentials from the environment in order to make the deployment more flexible.
The real deal happens inside api.py. This is where we are accepting the inference requests (files of hand drawn digits being uploaded) and forward them to the message broker.
We create a random UUID and attach it to the inference request, for our client to be able to retrieve the result later.
from typing import Union
from fastapi import FastAPI, UploadFile
from pika import BasicProperties
from pydantic import BaseModel
from PIL import Image
import numpy as np
import pickle
import uuid
from bridge import redis_client, rabbitmq_client
api = FastAPI()
class PendingClassificationDTO(BaseModel):
inference_id: str
class ClassificationResultDTO(BaseModel):
predicted_class: int
@api.post('/classify', response_model=PendingClassificationDTO, status_code=202)
async def classify(file: UploadFile):
im = Image.open(file.file)
image_data = np.array(im)
inference_id = str(uuid.uuid4())
rabbitmq_client.basic_publish(
exchange='', # default exchange
routing_key='mnist_inference_queue',
body=pickle.dumps(image_data),
properties=BasicProperties(headers={'inference_id': inference_id})
)
return PendingClassificationDTO(inference_id=inference_id)
@api.get('/result/{inference_id}', status_code=200,
response_model=Union[ClassificationResultDTO, PendingClassificationDTO])
async def classification_result(inference_id):
if not redis_client.exists(inference_id):
return PendingClassificationDTO(inference_id=inference_id)
result = redis_client.get(inference_id)
return ClassificationResultDTO(predicted_class=result)
api.py
Naturally, we need to define an additional endpoint which allows us to query the Redis data-store for the inference result, which might or might not be available.
If one is available, it's sent to the client upon request, if this is not the case, we send it back, implicitly asking to wait a little longer for the request to be processed.
Configuring the Worker
As the API is ready to take on all the requests and put them into the message queue, the logical next step is to implement the worker, in order to have those requests swiftly processed.
Again, we are splitting the logic into 2 parts to make for a somewhat more readable code. First we create a inference_model.py file which loads up the real PyTorch model and encapsulates the prediction and pre-processing workflow.
import torch
from torchvision.transforms import transforms
from model import MNISTNet
class MNISTInferenceModel:
def __init__(self):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Loading model for device {self.device}")
self.model = MNISTNet()
self.model.load_state_dict(torch.load("mnist_cnn.pt"))
self.model = self.model.eval()
self.model = self.model.to(self.device)
def infer(self, image_data):
preprocessed_image_data = self._preprocess(image_data)
prediction = self._predict(preprocessed_image_data)
return prediction
def _preprocess(self, image_data):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(),
transforms.Resize(28),
transforms.CenterCrop(28),
transforms.Normalize((0.1307,), (0.3081,)),
])
tensor = transform(image_data)
return torch.unsqueeze(tensor, dim=0)
def _predict(self, image_data):
with torch.inference_mode():
data = image_data.to(self.device)
output = self.model(data)
pred = output.argmax(dim=1, keepdim=True)
return pred.item()
inference_model.py
For this inference model to be useful, we'll finally also declare our worker in worker.py.
It will be responsible to wait for requests to come in, extract the payload (the uploaded image), pass it along to the inference model and store the result for later retrieval.
from pika import BasicProperties
from inference_model import MNISTInferenceModel
import pickle
from bridge import rabbitmq_client, redis_client
def callback(ch, method, properties: BasicProperties, body):
image_data = pickle.loads(body)
result = inference_model.infer(image_data)
print(f"Result: {result}")
redis_client.set(properties.headers["inference_id"], result)
ch.basic_ack(delivery_tag=method.delivery_tag)
inference_model = MNISTInferenceModel()
rabbitmq_client.basic_qos(prefetch_count=1)
rabbitmq_client.basic_consume(queue='mnist_inference_queue', on_message_callback=callback)
rabbitmq_client.start_consuming()worker.py
The worker is also, just like the API, utilizing the “bridge” in order to connect to the Redis data-store and the RabbitMQ message broker.
Lastly, the message will be acknowledged, giving the message broker the signal that it has been processed successfully.
Trying it out
As our setup is now complete, it's time to run the API and our worker(s) to see if everything is working the way it's supposed to.
First, we start up FastAPI.
python -m uvicorn api:api
Second, we start the worker(s). In fact, we can already instantiate the worker multiple times, to see if the task distribution works as anticipated. So for testing, let's start 2 instances of our workers.
python -m workerTo try out if the inference works, we'll submit multiple sample images from the MNIST dataset. A blurry 4, a 7 positioned at the bottom and a reasonably centered 3.


Inference test files
Next, we'll send 3 curl requests to our API, anticipating in response different inference UUIDs we can then use later to check the inference status.
curl -X POST 'http://localhost:8000/classify' --form 'file=@"mnist_3.jpeg"'
> {"inference_id":"bac0e10d-87e8-4f93-b102-f6816a32b66b"}
curl -X POST 'http://localhost:8000/classify' --form 'file=@"mnist_4.jpg"'
> {"inference_id":"8f021057-532a-47ac-896e-407fe14fb474"}
curl -X POST 'http://localhost:8000/classify' --form 'file=@"mnist_7.webp"'
> {"inference_id":"30684d7f-b86a-4014-9029-85554dccf3e7"}Great, we got an inference UUID back for each request. Looking at the terminal output of our 2 workers, we can also see that the task distribution worked successfully, as the first worker processed the 3 and the 7, while the second worker processed the 4.
By looking at the workers outputs, we already know the inference prediction, nevertheless we'll also test the last step, making sure that fetching the inference result on the client by providing the UUID works as expected.
curl -X GET 'http://localhost:8000/result/bac0e10d-87e8-4f93-b102-f6816a32b66b'
> {"predicted_class":3}
curl -X GET 'http://localhost:8000/result/8f021057-532a-47ac-896e-407fe14fb474'
> {"predicted_class":4}
curl -X GET 'http://localhost:8000/result/30684d7f-b86a-4014-9029-85554dccf3e7'
> {"predicted_class":7}And there they are, 3, 4 and 7, good stuff!
Great, what's next?
Possible next steps would be to containerize our solutions via Docker, such that they can be deployed a little easier to specific Docker machines or even to a Kubernetes cluster.
Also, very likely it would make sense to invest more time looking into the documentation of RabbitMQ and Redis, hardening the setup in case of lost connections or bad data that can't be processed by a worker. Furthermore, an expiration time for the results stored in Redis would probably make sense.
So on and so forth, lots of possibilities to improve the proposed setup, which unfortunately can't be covered all in one post.
Why not use Celery (Python Job Scheduler Library)?
Celery is very promising, and in fact this post started out building the setup with Celery, however at some point the downsides outweighed the upsides for me.
Machine learning inference tasks are very specific, and Celery is a distributed job scheduler with batteries included, meaning it comes with opinionated defaults. These defaults, however, might not be the best way to go about ML inference tasks.
So often it boils down to forcefully ripping out some batteries again to get to a proper solution. For example, by having to neglect its multithreaded nature and forcing one instance of it to be single threaded only, in order to make it work with CUDA.
Also, since Celery wants to be as easy as possible to use it, we find ourselves quickly dealing with unnecessary dependencies in the API, or “conditional imports” or dynamically loading classes via string parameters.
I'm not saying it's impossible, especially the last reference proves that it is very possible. Celery is a great tool, however under the circumstances of ML inference it doesn't allow me to separate the API from the worker as clearly as I'd like them to be. So take it with a grain of salt, as it's just my subjective opinion.
Congratulations!
You've come to an end, and by that end, you should now have a scalable solution to serve your GPU intensive ML models for inference!