Disaster Tweet Classification with RoBERTa and PyTorch
Approaching the Disaster Tweet Classification Kaggle challenge with NLP deep learning.
Text classification is one of the most common tasks in the natural language processing field. It can be applied to a wide variety of applications like spam filtering, sentiment analysis, home assistants, etc.
Today, Transformer architectures are the dominant models enabling state-of-the-art text classification. Even more dominant seem to be BERT based models and it's offsprings, which utilize Transformer Encoders to contextualize word-sequences.
In the following, we'll build a machine learning model with PyTorch, tackling the kaggle “Natural Language Processing with Disaster Tweets” Challenge utilizing the BERT based RoBERTa model.
Checking out the Data
While checking out the dataset, we split it right away into 2 chunks of train and validation set, as we'll need a validation set anyway.
import pandas as pd
from sklearn.model_selection import train_test_split
train_df = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
test_df = pd.read_csv("/kaggle/input/nlp-getting-started/test.csv")
train_df, val_df = train_test_split(train_df, test_size=0.2, random_state=42)| id | keyword | location | text | target |
|---|---|---|---|---|
| 7128 | military | Texas | Courageous and honest analysis of need to use Atomic Bomb in 1945. #Hiroshima70 Japanese military refused surrender. https://t.co/VhmtyTptGR | 1 |
| 4688 | engulfed | nan | @ZachZaidman @670TheScore wld b a shame if that golf cart became engulfed in flames. #boycottBears | 0 |
| 6984 | massacre | Cottonwood Arizona | Tell @BarackObama to rescind medals of 'honor' given to US soldiers at the Massacre of Wounded Knee. SIGN NOW & RT! https://t.co/u4r8dRiuAc | 1 |
| 4103 | drought | Spokane, WA | Worried about how the CA drought might affect you? Extreme Weather: Does it Dampen Our Economy? http://t.co/fDzzuMyW8i | 1 |
| 6706 | lava | Medan,Indonesia | @YoungHeroesID Lava Blast & Power Red #PantherAttack @JamilAzzaini @alifaditha | 0 |
We can see that additionally to the raw tweet text we get a keyword and a location feature, both of which can be null, though. For the sake of this post we drop the keyword and location columns as we'll only use the text column.
It should nevertheless be stressed that usually we should explore all features and make use of as much information as possible via feature engineering.
train_df = train_df.drop(["keyword", "location"], axis=1)
val_df = val_df.drop(["keyword", "location"], axis=1)
test_df = test_df.drop(["keyword", "location"], axis=1)Also, we can see that the text contains a lot of "noise" like the tweet link, some mentions, hashtags, etc. For our model to perform best, we need to clean the text a bit up.
Data Loading and Preprocessing
In order to efficiently process the textual data, we are going to create a PyTorch Dataset to be able to load the data quickly as well as to apply some preprocessing steps.
from torch.utils.data import Dataset
import numpy as np
import re
import nltk
import string
class TweetDataset(Dataset):
def __init__(self, dataframe, tokenizer):
texts = dataframe.text.values.tolist()
texts = [self._preprocess(text) for text in texts]
self._print_random_samples(texts)
self.texts = [tokenizer(text, padding='max_length',
max_length=150,
truncation=True,
return_tensors="pt")
for text in texts]
if 'target' in dataframe:
classes = dataframe.target.values.tolist()
self.labels = classes
def _print_random_samples(self, texts):
np.random.seed(42)
random_entries = np.random.randint(0, len(texts), 5)
for i in random_entries:
print(f"Entry {i}: {texts[i]}")
print()
def _preprocess(self, text):
text = self._remove_amp(text)
text = self._remove_links(text)
text = self._remove_hashes(text)
text = self._remove_retweets(text)
text = self._remove_mentions(text)
text = self._remove_multiple_spaces(text)
#text = self._lowercase(text)
text = self._remove_punctuation(text)
#text = self._remove_numbers(text)
text_tokens = self._tokenize(text)
text_tokens = self._stopword_filtering(text_tokens)
#text_tokens = self._stemming(text_tokens)
text = self._stitch_text_tokens_together(text_tokens)
return text.strip()
def _remove_amp(self, text):
return text.replace("&", " ")
def _remove_mentions(self, text):
return re.sub(r'(@.*?)[\s]', ' ', text)
def _remove_multiple_spaces(self, text):
return re.sub(r'\s+', ' ', text)
def _remove_retweets(self, text):
return re.sub(r'^RT[\s]+', ' ', text)
def _remove_links(self, text):
return re.sub(r'https?:\/\/[^\s\n\r]+', ' ', text)
def _remove_hashes(self, text):
return re.sub(r'#', ' ', text)
def _stitch_text_tokens_together(self, text_tokens):
return " ".join(text_tokens)
def _tokenize(self, text):
return nltk.word_tokenize(text, language="english")
def _stopword_filtering(self, text_tokens):
stop_words = nltk.corpus.stopwords.words('english')
return [token for token in text_tokens if token not in stop_words]
def _stemming(self, text_tokens):
porter = nltk.stem.porter.PorterStemmer()
return [porter.stem(token) for token in text_tokens]
def _remove_numbers(self, text):
return re.sub(r'\d+', ' ', text)
def _lowercase(self, text):
return text.lower()
def _remove_punctuation(self, text):
return ''.join(character for character in text if character not in string.punctuation)
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = -1
if hasattr(self, 'labels'):
label = self.labels[idx]
return text, labelWe remove mentions, links, hashtags, punctuations, and other stuff we deem not necessary for our model to come up with correct predictions.
Some of the code in the _preprocess method is commented out. This is due to the fact that the amount of preprocessing that should be done or is needed also depends on the chosen base model. Some models have for example been pre-trained on uncased text, some on cased text...
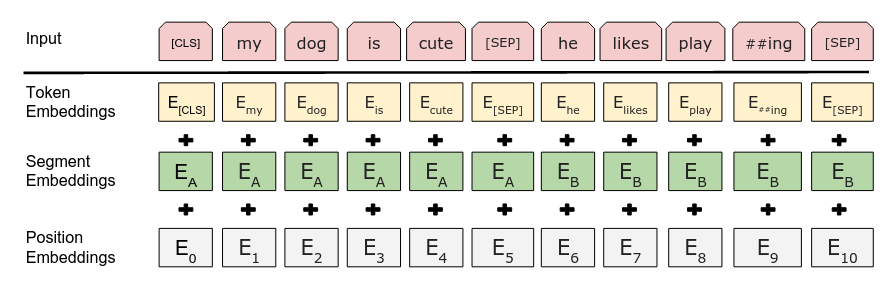
The tokenizer is then tokenizing our cleaned up character sequence, preparing it to be fed into a BERT based model.
Building the Classifier
In order to make use of our dataset and the preprocessed text corpora, we are going to need a classifier too.
from torch import nn
class TweetClassifier(nn.Module):
def __init__(self, base_model):
super(TweetClassifier, self).__init__()
self.bert = base_model
self.fc1 = nn.Linear(768, 32)
self.fc2 = nn.Linear(32, 1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input_ids, attention_mask):
bert_out = self.bert(input_ids=input_ids,
attention_mask=attention_mask)[0][:, 0]
x = self.fc1(bert_out)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return xOur custom PyTorch classifier takes the base model and sets up the MLP head for the downstream classification task. Notable here is the input size of the first linear layer of 768, which is going to correspond to the hidden layer dimension of our chosen base model for the sequence contextualization.
We pass in the input_ids and the attention_mask we obtained from our tokenization process, as an output we get a BaseModelOutputWithPoolingAndCrossAttentions which contains the state of the last hidden layer of the model, as well as the pooled output.
Theoretically, we could use either for our classification approach, but the most common method is to access the [CLS] token of the last hidden layer state. Which is exactly what we are doing by accessing [0][:,0] of the base model's output.
We are essentially transforming the output array of shape [BATCH_SIZE x SEQUENCE_LENGTH x HIDDEN_LAYER_DIM] to [BATCH_SIZE x HIDDEN_LAYER_DIM] accessing the first token of the sequence, namely the [CLS] token.
Setting up the training loop
In order to make use of our classifier, we build up a training loop.
We use BinaryCrossEntropyLoss as we are dealing with a binary classification task, and our model is built in such a way that via the Sigmoid function at the end it should output a nice probability of 0 (=no disaster) and 1 (=disaster).
import torch
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_dataloader, val_dataloader, learning_rate, epochs):
best_val_loss = float('inf')
early_stopping_threshold_count = 0
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
criterion = nn.BCELoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
model = model.to(device)
criterion = criterion.to(device)
for epoch in range(epochs):
total_acc_train = 0
total_loss_train = 0
model.train()
for train_input, train_label in tqdm(train_dataloader):
attention_mask = train_input['attention_mask'].to(device)
input_ids = train_input['input_ids'].squeeze(1).to(device)
train_label = train_label.to(device)
output = model(input_ids, attention_mask)
loss = criterion(output, train_label.float().unsqueeze(1))
total_loss_train += loss.item()
acc = ((output >= 0.5).int() == train_label.unsqueeze(1)).sum().item()
total_acc_train += acc
loss.backward()
optimizer.step()
optimizer.zero_grad()
with torch.no_grad():
total_acc_val = 0
total_loss_val = 0
model.eval()
for val_input, val_label in tqdm(val_dataloader):
attention_mask = val_input['attention_mask'].to(device)
input_ids = val_input['input_ids'].squeeze(1).to(device)
val_label = val_label.to(device)
output = model(input_ids, attention_mask)
loss = criterion(output, val_label.float().unsqueeze(1))
total_loss_val += loss.item()
acc = ((output >= 0.5).int() == val_label.unsqueeze(1)).sum().item()
total_acc_val += acc
print(f'Epochs: {epoch + 1} '
f'| Train Loss: {total_loss_train / len(train_dataloader): .3f} '
f'| Train Accuracy: {total_acc_train / (len(train_dataloader.dataset)): .3f} '
f'| Val Loss: {total_loss_val / len(val_dataloader): .3f} '
f'| Val Accuracy: {total_acc_val / len(val_dataloader.dataset): .3f}')
if best_val_loss > total_loss_val:
best_val_loss = total_loss_val
torch.save(model, f"best_model.pt")
print("Saved model")
early_stopping_threshold_count = 0
else:
early_stopping_threshold_count += 1
if early_stopping_threshold_count >= 1:
print("Early stopping")
breakFor each epoch we calculate the loss as well as the accuracy on the train and the validation set. We apply early stopping and store the best model, according to the validation loss, for later usage.
Training our classifier
As our final step for the text classification we put it all together, we initialize our train and validation datasets, instantiate our chosen RoBERTa model and start a training loop.
from transformers import AutoTokenizer, AutoModel
from torch.utils.data import DataLoader
torch.manual_seed(0)
np.random.seed(0)
BERT_MODEL = "roberta-base"
tokenizer = AutoTokenizer.from_pretrained(BERT_MODEL)
base_model = AutoModel.from_pretrained(BERT_MODEL)
train_dataloader = DataLoader(TweetDataset(train_df, tokenizer), batch_size=8, shuffle=True, num_workers=0)
val_dataloader = DataLoader(TweetDataset(val_df, tokenizer), batch_size=8, num_workers=0)
model = TweetClassifier(base_model)
learning_rate = 1e-5
epochs = 5
train(model, train_dataloader, val_dataloader, learning_rate, epochs)
> Epochs: 1 | Train Loss: 0.471 | Train Accuracy: 0.786 | Val Loss: 0.427 | Val Accuracy: 0.818
> Saved model
> Epochs: 2 | Train Loss: 0.372 | Train Accuracy: 0.844 | Val Loss: 0.378 | Val Accuracy: 0.842
> Saved model
> Epochs: 3 | Train Loss: 0.311 | Train Accuracy: 0.875 | Val Loss: 0.405 | Val Accuracy: 0.847
> Early stoppingOur model achieves 84.2% validation accuracy. The third model achieved an even higher score, nevertheless we stick to the second one as the validation loss reached a minima here, indicating higher confidence in the predictions.
Predicting for the test data
Since our model is working well on the validation dataset, it's time to make it predict disasters for the test data.
def get_text_predictions(model, loader):
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
model = model.to(device)
results_predictions = []
with torch.no_grad():
model.eval()
for data_input, _ in tqdm(loader):
attention_mask = data_input['attention_mask'].to(device)
input_ids = data_input['input_ids'].squeeze(1).to(device)
output = model(input_ids, attention_mask)
output = (output > 0.5).int()
results_predictions.append(output)
return torch.cat(results_predictions).cpu().detach().numpy()Analogously to the training loop, we define ourselves a method to conveniently extract the predictions done by our model. As our model is returning a probability between 0 and 1 we use a 50% threshold for our target classification.
Next we load up the previously saved model and set up the test data loader.
To store our predictions we use the given "sample_submission.csv", which already contains the test IDs and the sample target, which we are going to overwrite with the predictions of our model.
model = torch.load("best_model.pt")
test_dataloader = DataLoader(TweetDataset(test_df, tokenizer),
batch_size=8, shuffle=False, num_workers=0)
sample_submission = pd.read_csv("/kaggle/input/nlp-getting-started/sample_submission.csv")
sample_submission["target"] = get_text_predictions(model, test_dataloader)
display(sample_submission.head(20))
sample_submission.to_csv("submission.csv", index=False)As a last step, we save our predictions to disk in a "submission.csv" file.
In this case, our predictions yield an F1 score of ~83% which is not too bad, lower than our previous validation score, but not shabby at all!
Improvements
As mentioned in the beginning, usually we wouldn't just drop any other information and solely make our predictions based on the given text data. The additional columns location and keyword could be, and in fact are, very useful to improve our predictions.
One way to go about it is to do intensive data analysis of the correlation of location and keyword with a disaster happening or not. Also, pruning, cleaning and grouping are not of the table.
At a later stage one could then combine our text based predictions with location and keyword information and have a standard machine learning technique like a Decision Tree, Support Vector Machine, ... make a final classification.
If you are interested in one possible more "elaborate" solution, you can check out my notebook which does exactly this. But of course other approaches are possible, which likely yield even better results. So I encourage you to try out other approaches too!