Experimenting with FreeGBDT for NLI Fine-Tuning
Experimenting with "Enhancing Transformers with Gradient Boosted Decision Trees for NLI Fine-Tuning". A deep dive into the FreeGBDT paper.
Natural Language Inference (NLI), commonly understood as common sense reasoning, is one of the core parts of the much bigger field of Natural Language Understanding (NLU), being an essential part in the process of enabling human-computer interaction solely by language.
In the following, I'd like to dive a bit deeper into the paper Enhancing Transformers with Gradient Boosted Decision Trees for NLI Fine-Tuning by Benjamin Minixhofer, Milan Gritta and Ignacio Iacobacci.
Wherein they propose "FreeGBDT", a novel technique to improve current NLI systems via Gradient Boosted Decision Trees instead of the defacto standard MLP head approach.
We'll dig into the paper, summarize the core ideas, try to reproduce the results, further experiment with the technique on another base model, evaluate and compare our experiment results with the ones from the paper.
Core Components
Let's quickly introduce the core building blocks one needs to understand in order to make sense of the ideas behind FreeGBDT. We're only going roughly over them, as each of them would eventually be worth its own article.
Natural Language Inference
Natural Language Inference is the task of determining whether a hypothesis is true (entailment), false (contradiction), or undetermined (neutral) given a premise.
Premise: “A man is waiting at the window of a restaurant which serves sandwiches”
- "The person is waiting to be served his food" - Entailment
- "The person is looking to order a grilled cheese sandwich" - Neutral
- "The man is waiting in line for the bus" - Contradiction
The problem itself can either be defined as a 3 label classification problem (Eintailment, Neutral, Contradiction) or as a 2 label classification problem (Entailment, No Entailment).
Transformers & BERT
Transformers are a deep learning architecture originally introduced for machine translation and is since then widely used on various tasks for sequence encoding and sequence decoding.
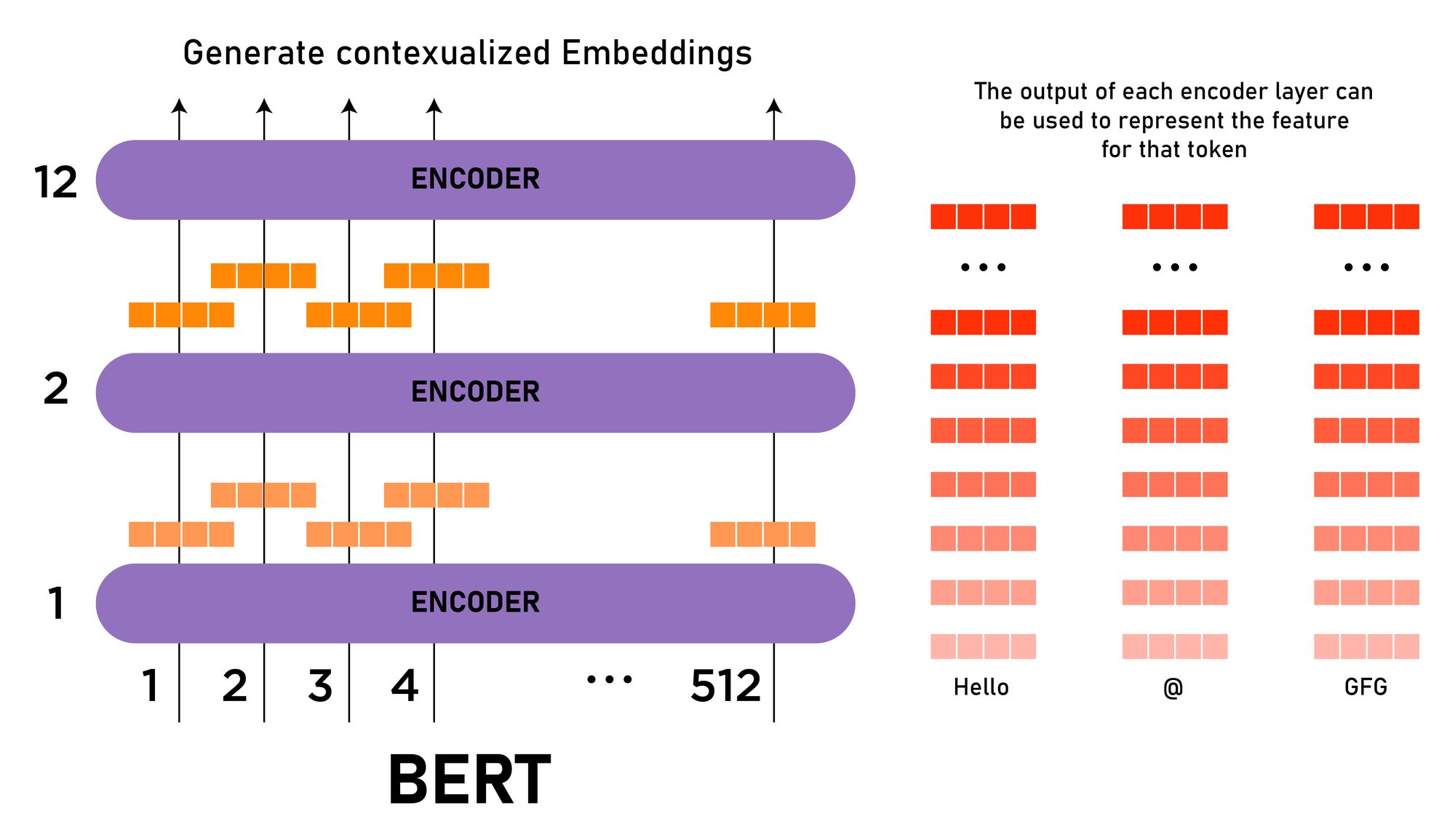
BERT is a transformers based machine learning architecture, it uses multiple Transformer Encoder instances to learn contextual embeddings for words and sequences.
Gradient Boosted Decision Trees
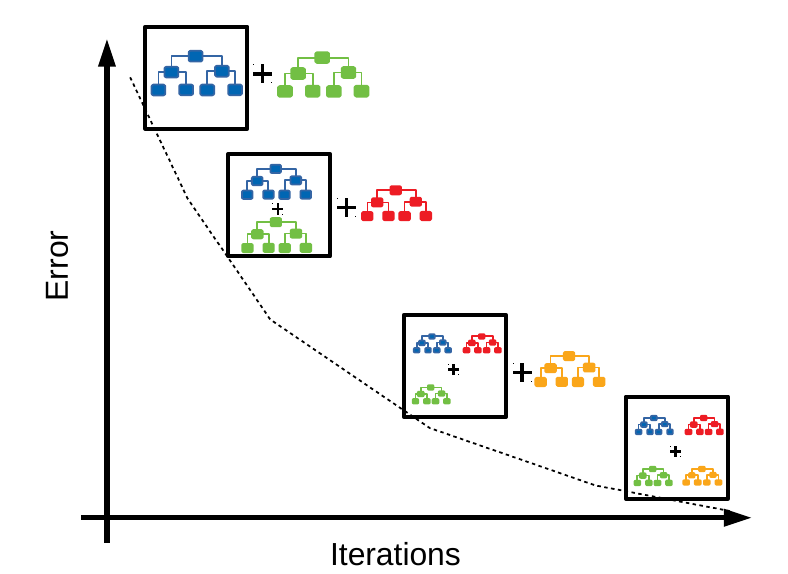
Gradient Boosting is a machine learning technique, giving a prediction in the form of an ensemble decision which is generated by sequentially boosting decision trees, having them learn from the errors of already generated ensemble candidates.
They have good performance on dense, numerical features and are effective where the ratio of the number of samples with respect to the number of features is low.
The Paper – 3 Ideas for Comparison
The paper speaks about 3 main ideas for comparison, with different fine-grained adjustments for each of them.
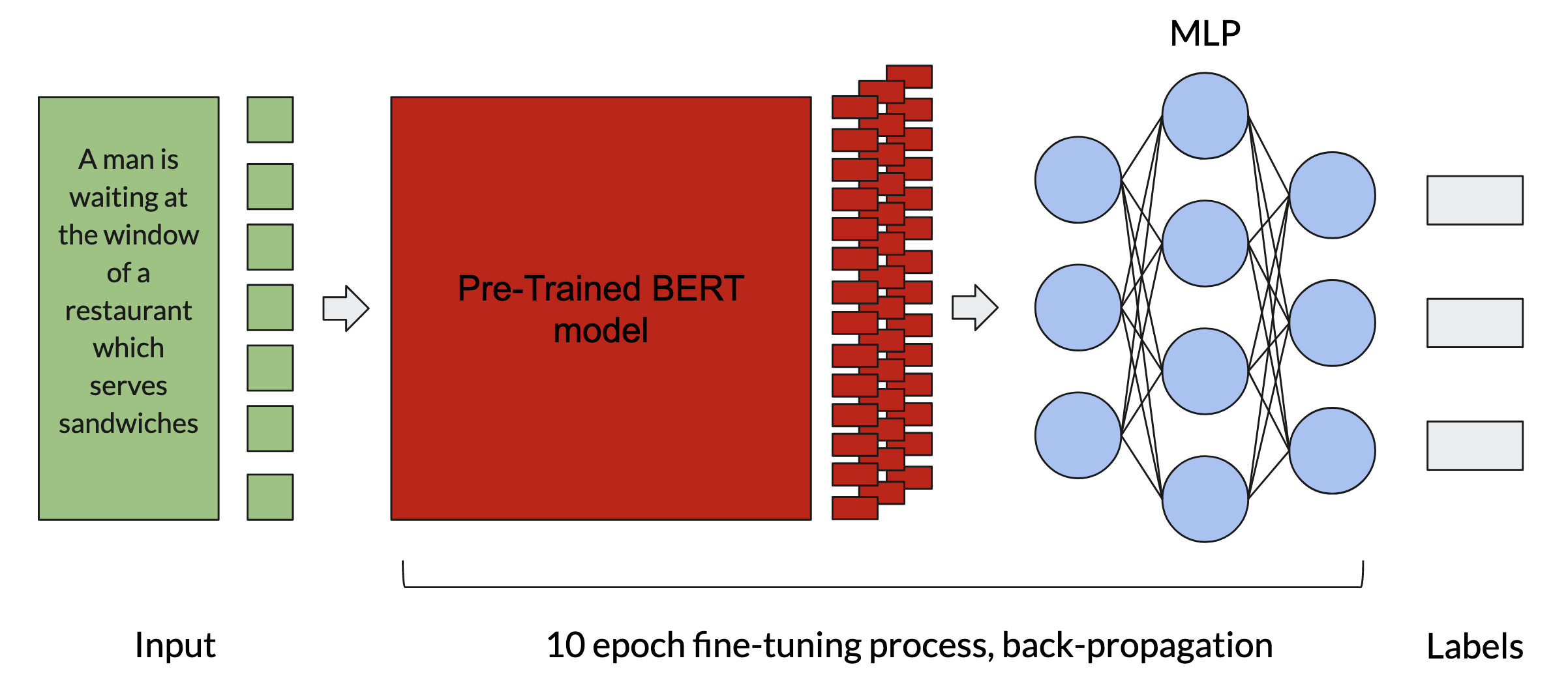
The Classical MLP Head Approach
- Choose a strong pre-trained base model
- Fit MLP head for label classification, fine-tune model combination for downstream NLI task
The Regular Tree Approach
- Choose a strong pre-trained base model
- Fit MLP head, fine-tune model combination for downstream NLI task
- Cut off MLP head and fit Gradient Boosting Decision Tree instead for NLI classification (additional forward pass needed)
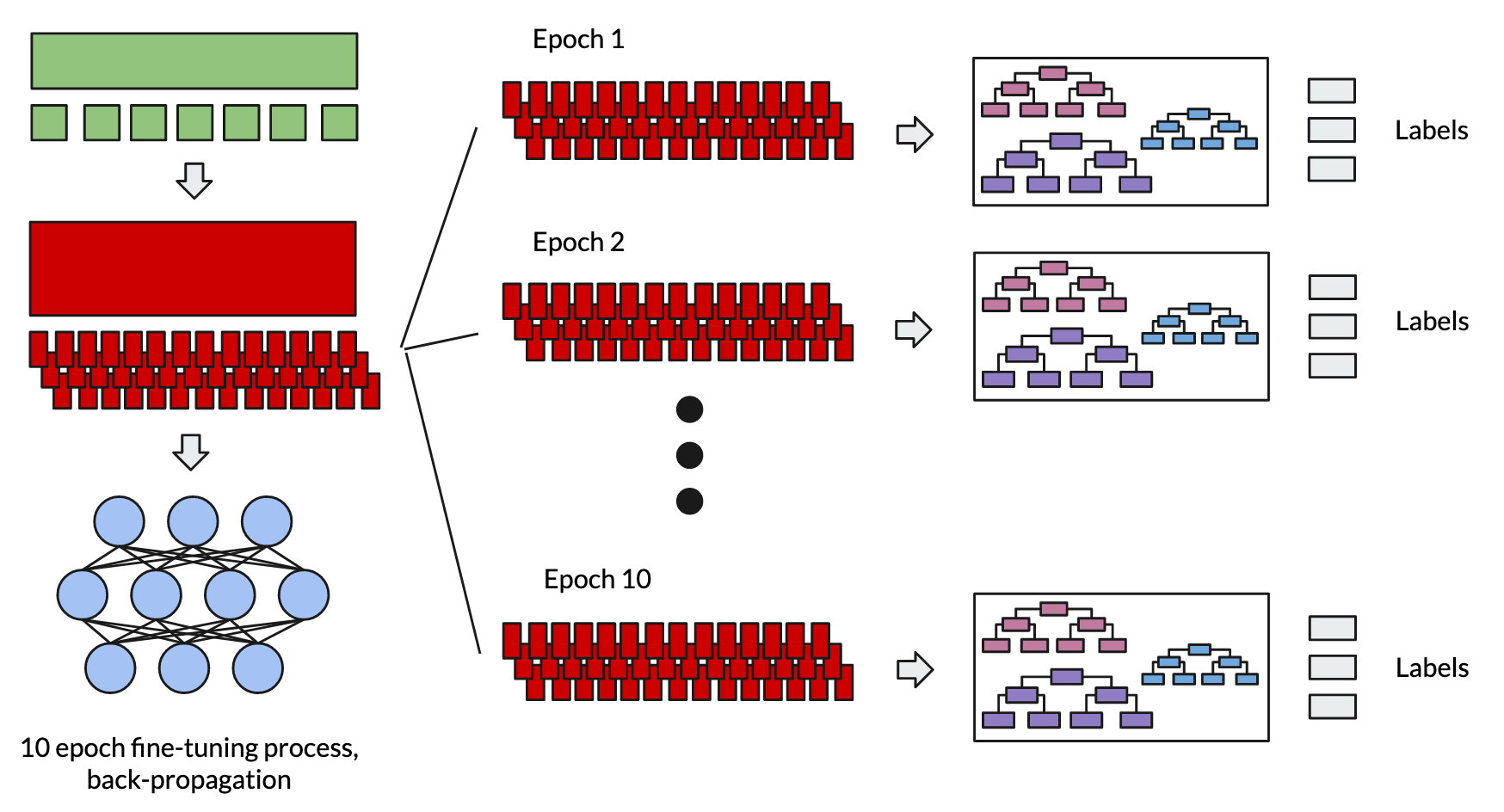
It's worth to make clear that f.e. if we stop training after epoch 1 already, this is comparable to training for one epoch, then doing an additional forward pass to generate the training data for the GBDT, then cutting off the MLP head and fitting the GBDT head instead.
Same goes for epoch 2 which would be comparable to 2 epochs of training, then doing an additional forward pass, then cutting off the MLP head and fitting the GBDT head instead. So on and so forth…
The FreeGBDT Approach
- Choose a strong pre-trained base model
- Fit MLP head, fine-tune model combination for downstream NLI task
- While fine-tuning, store the intermediate features of the base model (No additional forward pass)
- Cut off MLP head and fit a Gradient Boosting Decision Tree on the whole range of intermediate features for NLI classification
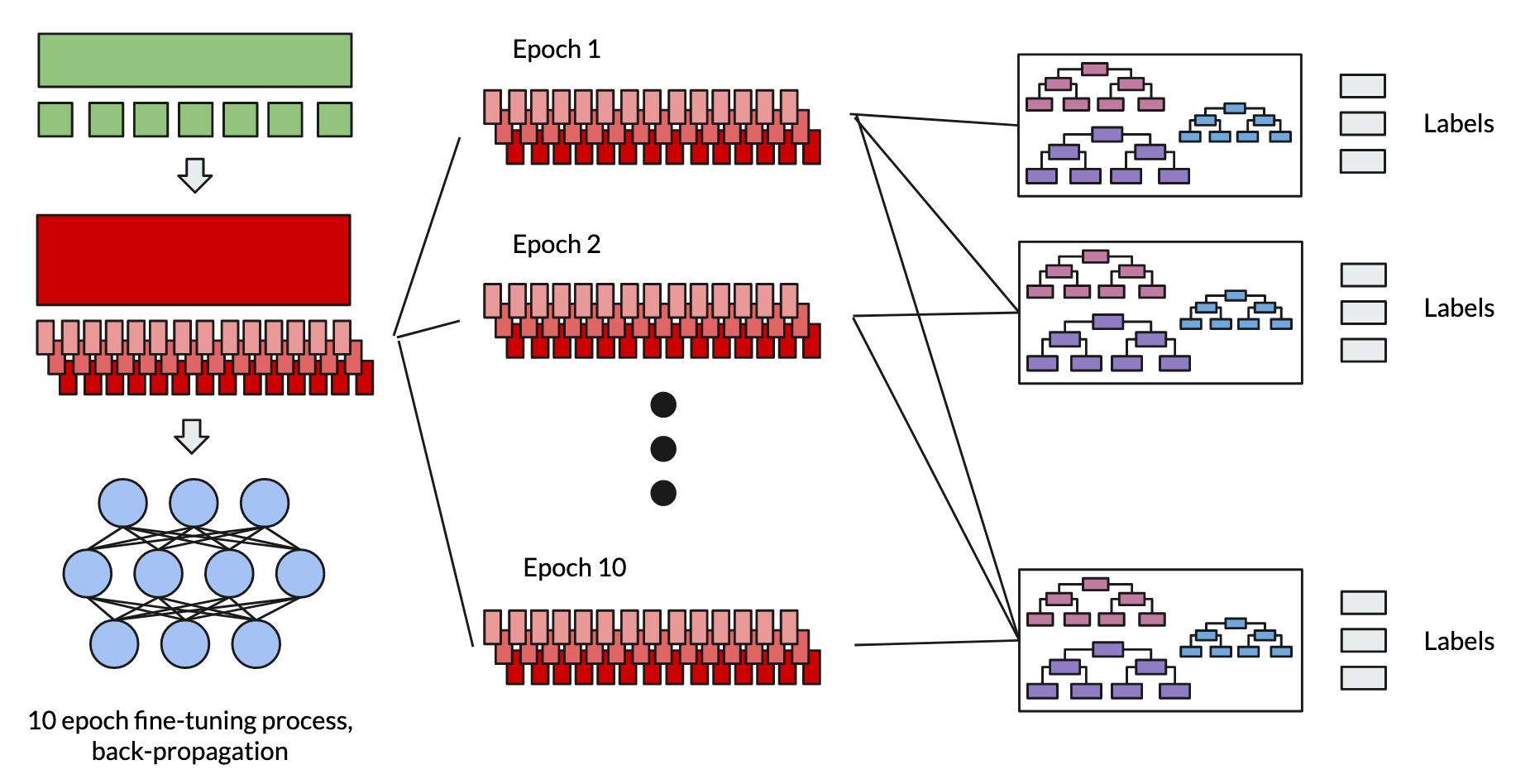
We can see 2 main differences to the regular tree based approach.
First, the results of the epochs are cumulated, yielding for each epoch more and more training data to fit our GBDT head.
Second, already the intermediate features are used, which eliminates the necessity of an additional forward pass to generate the training data for our GBDT head.
Additionally, we can see how the name "FreeGBDT" came together. As no additional forward pass is needed while preparing the data for the GBDT, we basically get the opportunity to use FreeGBDT later on for free. Also a lot more data is "generated" for the GBDT to be trained on.
The Comparison Setup
As we have a basic understanding of how the methods differ from each other, we can go on trying to reproduce the results in order to make sure we aren't doing something fundamentally wrong as soon as we start our own experiments.
The Datasets
In order to save time and some computational resources, we are not going to fully reproduce all 20 test runs per method with all the 5 datasets from the paper. Rather, we limit ourselves to the 3 smaller datasets, and we are only aiming for 3 test runs per method with the smaller datasets.
Which implies that we are going to stick to the 3 datasets:
- Commitment Bank (CB)
- Counterfactual NLI (CNLI)
- Recognizing Textual Entailment (RTE)
The Base Models
The paper uses roberta-large-mnli as base model to contextualize the data, hence we are also going to use this model to reproduce the data. However, down the line we are going to experiment with the much smaller distilroberta-base model.
These 2 models differ in two ways, the obvious one being that the roberta-large-mnli model is much bigger than the distilroberta-base model. Additionally, the roberta-large-mnli model is already pre-trained on another NLI dataset, namely the Multi-Genre Natural Language Inference (MNLI) dataset.
The GBDT Head
For the GBDT implementation we stick closely to the one used in the paper, being a LightGBM implementation with 1o boosting rounds for the CB, CNLI and RTE dataset.
The Comparison Results
We are going to compare our results with the validation set results from the paper, as the test results have mostly been obtained via submissions to public leaderboards.

Reproducing the Results
Having the comparison setup clarified, it's time to spin up our GPU and start training.
To get started I used the official code linked in the paper, however, I had to make some adjustments to get it to work properly due to some computing resource constraints.
But basically I only added checkpointing the epoch results to resume training in case of interruptions and used np.memmap instead of plain numpy arrays at some occasions to keep the RAM consumption low, etc.
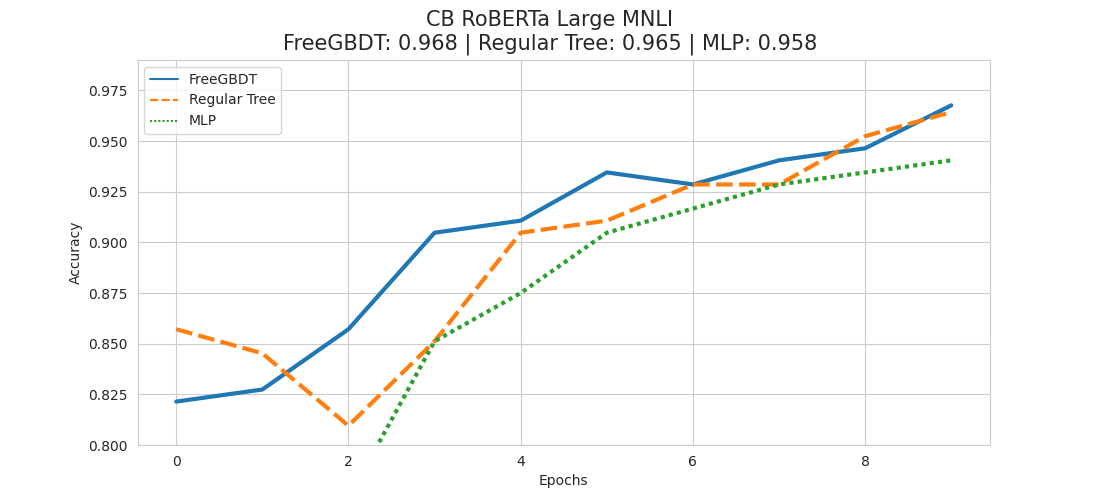
Reproduction – CB RoBERTa Large MNLI
We can observe that indeed in our results the FreeGBDT method takes the lead, leaving the regular tree approach in the second place followed by the classical MLP head method.
It's probably worth mentioning that we can see also that already early on in the training stage, FreeGBDT is taking the lead.
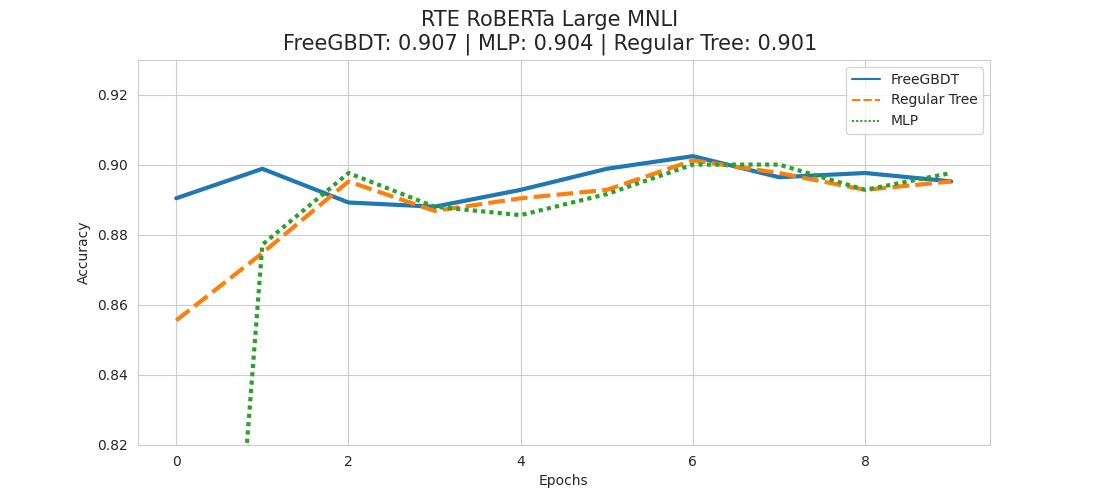
Reproduction – RTE RoBERTa Large MNLI
Although the results seem to be not as clear, as they are quite packed together, we are able to report similar outcomes for the RTE case. This time having the MLP head sitting in second place.
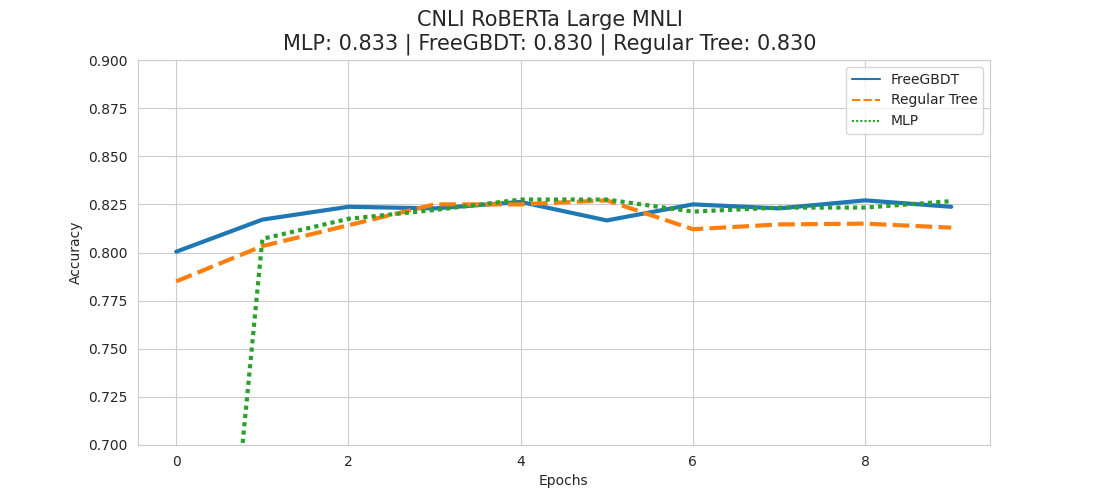
Reproduction - CNLI RoBERTa Large MNLI
This time we were not able to fully reproduce the results, as in this case the MLP head seems to be doing best with a first-to-second-place difference of 0.003 accuracy points.
That's not a lot, and looking at the results we are comparing with, we can see that also in the paper they report only a difference of 0.04 percentage points between the FreeGBDT and the MLP method. (Mind the difference between accuracy points and percentage points here)
It seems reasonable to discard this difference due to its very small nature and the low number of test runs we did in our reproduction scenario. Overall the results seem to be comparable with the ones of the paper.
Discussion – Reproduction Results
As we were able to successfully reproduce the results of the paper, it might be a good time to take a minute and think about why this FreeGBDT method outperforms the other approaches or is at least on par with them.
For one, it seems that the model is benefitting from the big, and already for an NLI task pre-trained, roberta-large-mnli model, hence it's able to early on in the training stage use the contextualized knowledge of the model well.
Also, since the early epochs already yield quite good results, a lot more good training data can be “generated” by accumulating the model output of each trainingsbatch.
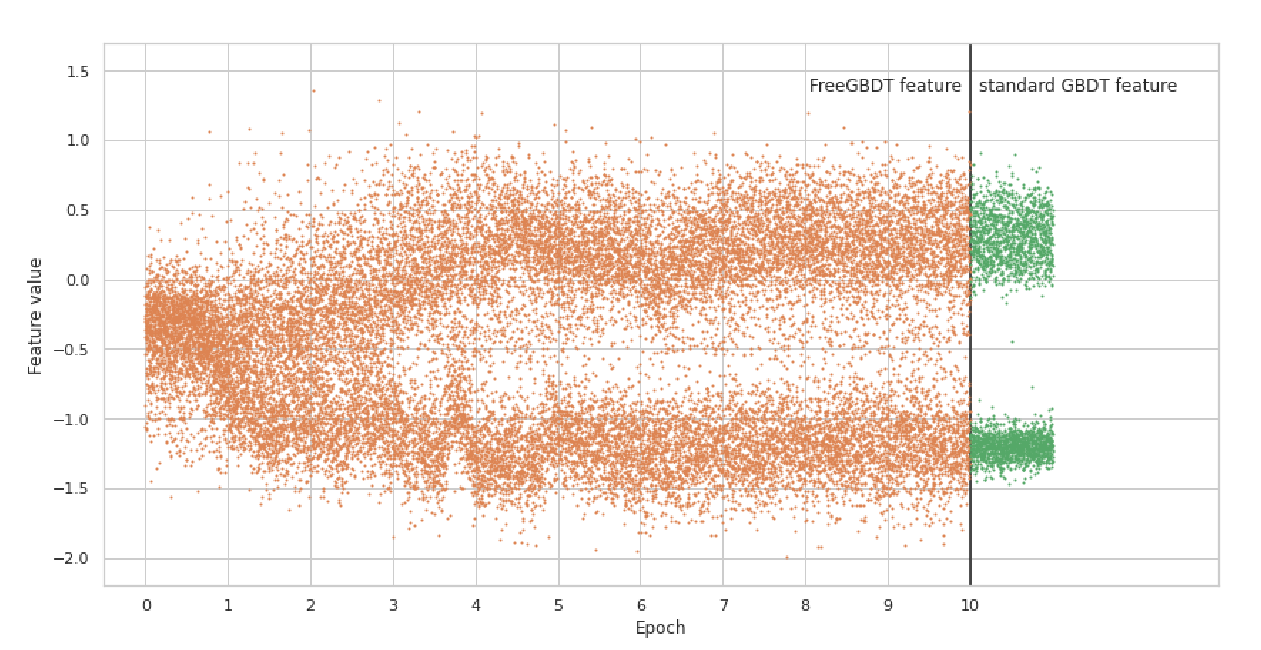
As illustrated in the chart directly taken from the paper itself we can see the feature value distribution of FreeGBDT over all epochs, compared with the standard tree approach. It shows quite well the difference in the amount of available training data for the GBDT head, as well as the quality of the generated output already early on.
However, it also seems to be a bit of an “in-between” situation, FreeGBDT can improve the already strong results of the base model a bit, as it benefits from the good results early on. However, it can also only improve the results of the base model so much, as the base model is already very strong.
Experimenting with DistilRoBERTa Base
Now that we finished the reproduction part, we can be sure that our reproduction methods aren't erroneous, and we also made sure to understand how exactly everything internally works. So it's time to conduct our own experiments with the much smaller distilroberta-base model.
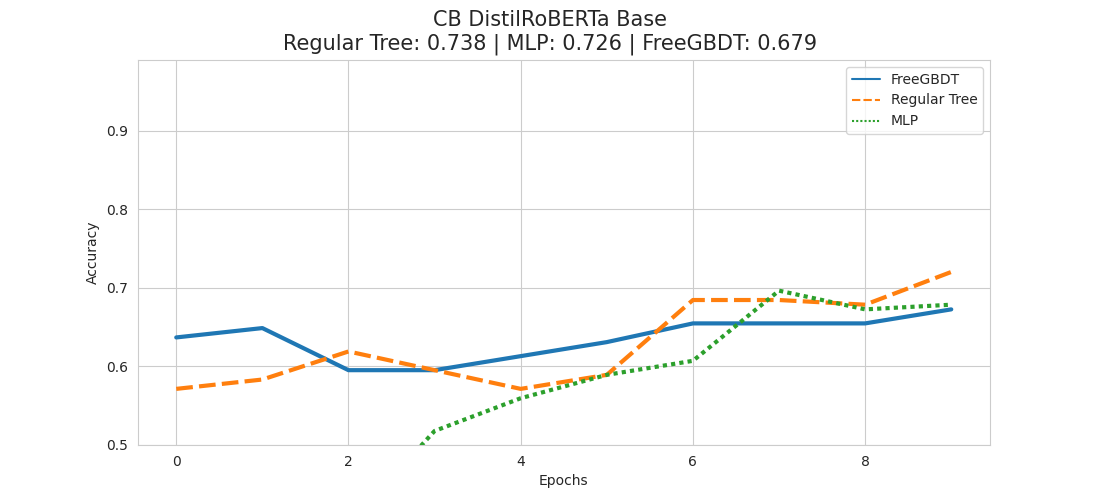
Experiment – CB DistilRoBERTa Base
Not very surprisingly we get worse results than with the bigger, already NLI experienced roberta-large-mnli model.
But contrary to the bigger model, we find the winner this time to be the regular tree approach, and FreeGBDT actually coming in last.
We might also be able to observe that even at the later stage the results are still varying a lot, which might be an indicator that we might benefit from more than 10 epochs of training for this dataset.
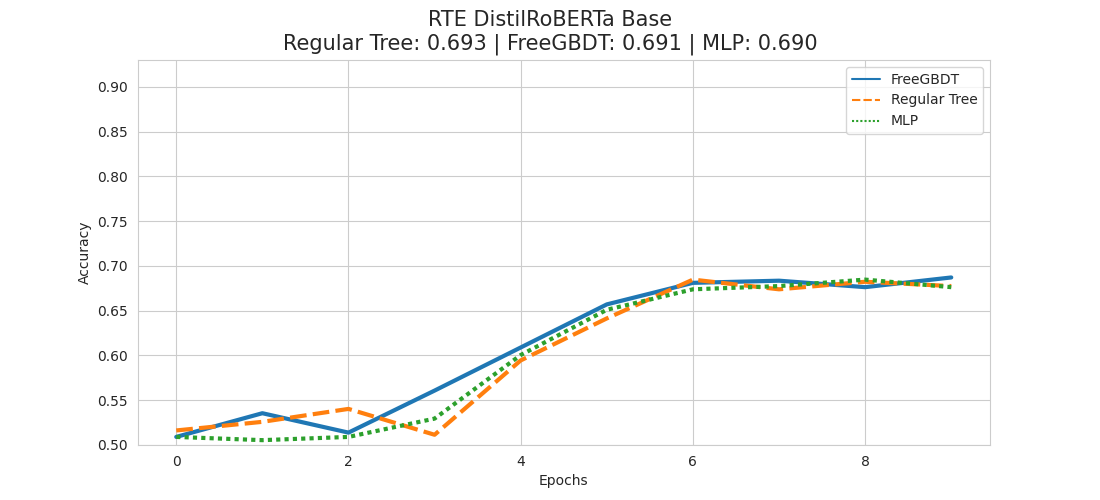
Experiment – RTE DistilRoBERTa Base
Also this time we can see that the regular tree approach is in the lead, this time followed by the FreeGBDT method and the MLP head coming in last.
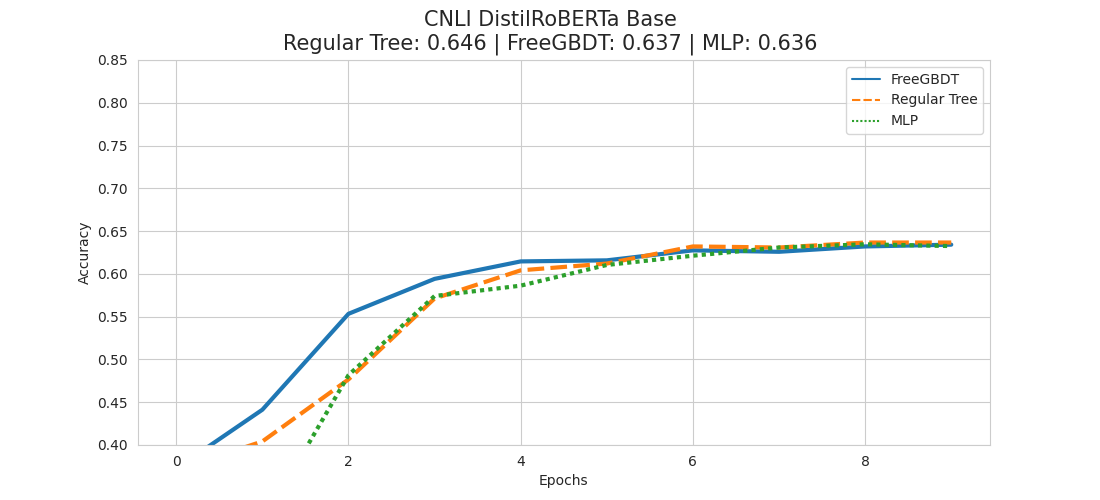
Experiment - CNLI DistilRoBERTa Base
Analogously to the RTE experiment, we again have the regular tree approach in the lead, followed by FreeGBDT and MLP.
Discussion – Experiment Results
We saw that in all 3 of our experiments the regular tree based approach took the lead when having a model as basis that is smaller, and has not been pre-trained for an NLI task already. FreeGBDT is often very close, but not the top performing variant.
This might be due to the size of the model being too small to capture the nuances of the text well enough in its contextualization. Possibly it might also be that the model lacks the knowledge of being pre-trained on the MNLI dataset before tackling our datasets, hence it's not able to benefit from good results early on in the training stage.
It seems that in our experiment setting, a regular tree based approach seems to be the better method. However, it's not yet clear where the FreeGBDT method can be positioned.
As we noticed for the CB dataset that it might make sense to give it more time to reach its full potential, we conduct another set of experiments, but having them run 20 epochs instead of 10 this time.
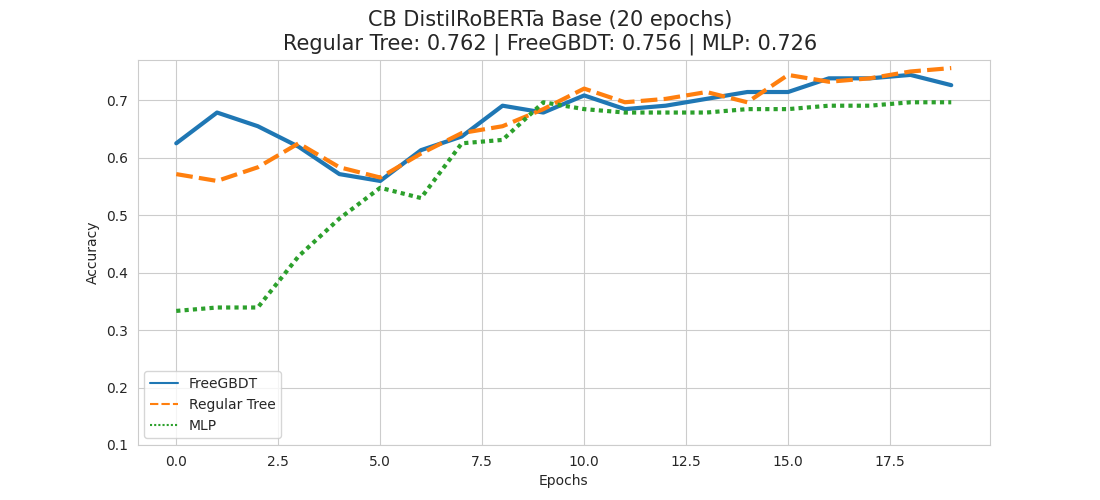
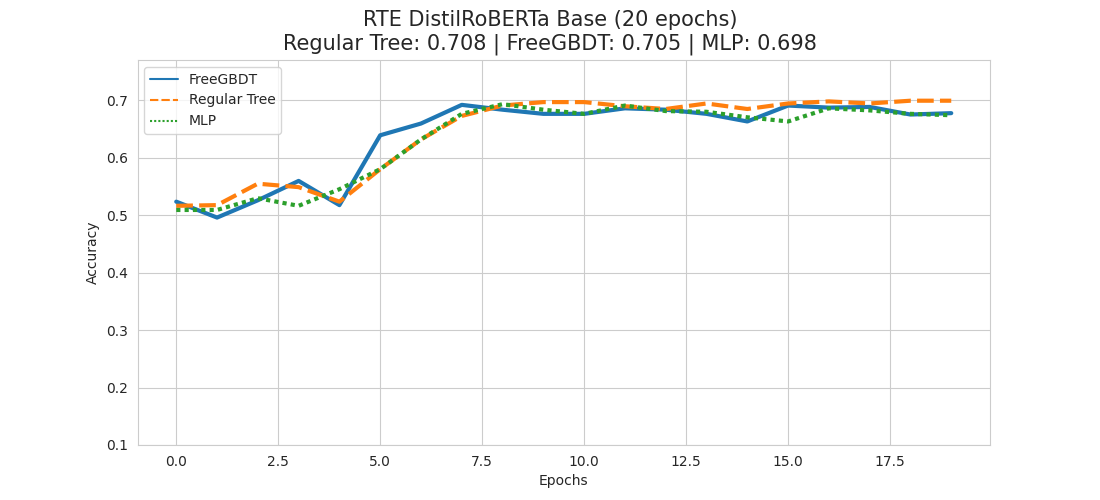
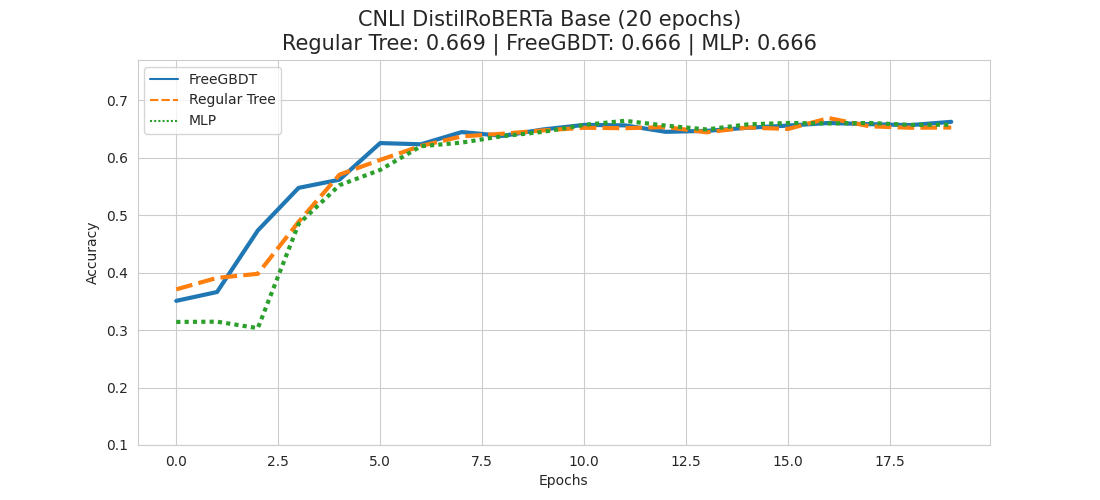
By giving our models more time to reach their full potential, we can see quite a clear pattern now.
Cleary, in all 3 experiments the regular tree based approach seems to yield the best results, while FreeGBDT is to be positioned in second place closely following the regular tree approach. The classical MLP head variant is coming in last in all 3 cases.
Conclusion
After our reproduction efforts and additional experiments we can conclude synonymously to the paper, that tree based approaches, be it a regular tree based approach or the proposed FreeGBDT method, seem to be viable alternatives to the classical MLP head approach for NLI tasks and possibly for other NLP challenges as well.
Nevertheless, depending on the chosen base model and the objectives of the task we'd like to accomplish, one might want to check both versions, the FreeGBDT and the regular tree based approach.
Diving Deeper
Some related resources to get an even deeper understanding of some of the technologies involved.
- The Illustrated Transformer
- Visualizing A Neural Machine Translation Model
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- FreeGBDT Github
- SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems